David N. Nicholson 0000-0003-0002-5761
· danich1
Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania
· Funded by GBMF4552
Daniel S. Himmelstein 0000-0002-3012-7446
· dhimmel
· dhimmel
Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania
· Funded by GBMF4552
Casey S. Greene 0000-0001-8713-9213
· cgreene
· GreeneScientist
Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania
· Funded by GBMF4552 and R01 HG010067
Knowledge graphs support biomedical research efforts by providing contextual information for biomedical entities, constructing networks, and supporting the interpretation of high-throughput analyses.
These databases are populated via manual curation, which is challenging to scale with an exponentially rising publication rate.
Data programming is a paradigm that circumvents this arduous manual process by combining databases with simple rules and heuristics written as label functions, which are programs designed to annotate textual data automatically.
Unfortunately, writing a useful label function requires substantial error analysis and is a nontrivial task that takes multiple days per function.
This bottleneck makes populating a knowledge graph with multiple nodes and edge types practically infeasible.
Thus, we sought to accelerate the label function creation process by evaluating how label functions can be re-used across multiple edge types.
Results
We obtained entity-tagged abstracts and subsetted these entities to only contain compounds, genes, and disease mentions.
We extracted sentences containing co-mentions of certain biomedical entities contained in a previously described knowledge graph, Hetionet v1.
We trained a baseline model that used database-only label functions and then used a sampling approach to measure how well adding edge-specific or edge-mismatch label function combinations improved over our baseline.
Next, we trained a discriminator model to detect sentences that indicated a biomedical relationship and then estimated the number of edge types that could be recalled and added to Hetionet v1.
We found that adding edge-mismatch label functions rarely improved relationship extraction, while control edge-specific label functions did.
There were two exceptions to this trend, Compound-binds-Gene and Gene-interacts-Gene, which both indicated physical relationships and showed signs of transferability.
Across the scenarios tested, discriminative model performance strongly depends on generated annotations.
Using the best discriminative model for each edge type, we recalled close to 30% of established edges within Hetionet v1.
Conclusions
Our results show that this framework can incorporate novel edges into our source knowledge graph.
However, results with label function transfer were mixed.
Only label functions describing very similar edge types supported improved performance when transferred.
We expect that the continued development of this strategy may provide essential building blocks to populating biomedical knowledge graphs with discoveries, ensuring that these resources include cutting-edge results.
Introduction
Knowledge bases are essential resources that hold complex structured and unstructured information.
These resources have been used to construct networks for drug repurposing discovery [1,2,3] or as a source of training labels for text mining systems [4,5,6].
Populating knowledge bases often requires highly trained scientists to read biomedical literature and summarize the results through manual curation [7].
In 2007, researchers estimated that filling a knowledge base via manual curation would require approximately 8.4 years to complete [8].
As the rate of publications increases exponentially [doi:10.1002/asi.23329?], using only manual curation to populate a knowledge base has become nearly impractical.
Relationship extraction is one of several solutions to the challenge posed by an exponentially growing body of literature [7].
This process creates an expert system to automatically scan, detect, and extract relationships from textual sources.
These expert systems fall into three types: unsupervised, rule-based, and supervised systems.
Unsupervised systems extract relationships without the need for annotated text.
These approaches utilize linguistic patterns such as the frequency of two entities appearing in a sentence together more often than chance, commonly referred to as co-occurrence [9,10,11,12,13,14,15,16,17].
For example, a possible system would say gene X is associated with disease Y because gene X and disease Y appear together more often than chance [9].
Besides frequency, other systems can utilize grammatical structure to identify relationships [18].
This information is modeled in the form of a tree data structure, termed a dependency tree.
Dependency trees depict words as nodes, and edges represent a word’s grammatical relationship with one another.
Through clustering on these generated trees, one can identify patterns that indicate a biomedical relationship [18].
Unsupervised systems are desirable since they do not require well-annotated training data; however, precision may be limited compared to supervised machine learning systems.
Rule-based systems rely heavily on expert knowledge to perform relationship extraction.
These systems use linguistic rules and heuristics to identify critical sentences or phrases that suggest the presence of a biomedical relationship [19,20,21,22,23,24].
For example, a hypothetical extractor focused on protein phosphorylation events would identify sentences containing the phrase “gene X phosphorylates gene Y” [19].
These approaches provide exact results, but the quantity of positive results remains modest as sentences consistently change in form and structure.
For this project, we constructed our label functions without the aid of these works; however, the approaches mentioned in this section provide substantial inspiration for novel label functions in future endeavors.
Supervised systems depend on machine learning classifiers to predict the existence of a relationship using biomedical text as input.
These classifiers can range from linear methods such as support vector machines [25,26] to deep learning [27,28,29,30,31,32], which all require access to well-annotated datasets.
Typically, these datasets are usually constructed via manual curation by individual scientists [33,34,35,36,37] or through community-based efforts [38,39,40].
Often, these datasets are well annotated but are modest in size, making model training hard as these algorithms become increasingly complex.
Distant supervision is a paradigm that quickly sidesteps manual curation to generate large training datasets.
This technique assumes that positive examples have been previously established in selected databases, implying that the corresponding sentences or data points are also positive [4].
The central problem with this technique is that generated labels are often of low quality, resulting in many false positives [41].
Despite this caveat there have been notable effort using this technique [42,43,44].
Data programming is one proposed solution to amend the false positive problem in distant supervision.
This strategy combines labels obtained from distant supervision with simple rules and heuristics written as small programs called label functions [45].
These outputs are consolidated via a noise-aware model to produce training labels for large datasets.
Using this paradigm can dramatically reduce the time required to obtain sufficient training data; however, writing a helpful label function requires substantial time and error analysis.
This dependency makes constructing a knowledge base with a myriad of heterogenous relationships nearly impossible as tens or hundreds of label functions are necessary per relationship type.
This paper seeks to accelerate the label function creation process by measuring how label functions can be reused across different relationship types.
We hypothesized that sentences describing one relationship type might share linguistic features such as keywords or sentence structure with sentences describing other relationship types.
If this hypothesis were to, one could drastically reduce the time needed to build a relation extractor system and swiftly populate large databases like Hetionet v1.
We conducted a series of experiments to estimate how label function reuse enhances performance over distant supervision alone.
As biomedical data comes in various forms (e.g. publications, electronic health records, images, genomic sequences, etc.), we chose to subset this space to only include open-access biomedical publications available on pubmed.
We focused on relationships that indicated similar types of physical interactions (i.e., Gene-binds-Gene and Compound-binds-Gene) and two more distinct types (i.e., Disease-associates-Gene and Compound-treats-Disease).
Methods and Materials
Hetionet
Hetionet v1 [3] is a heterogeneous network that contains pharmacological and biological information.
This network depicts information in the form of nodes and edges of different types.
Nodes in this network represent biological and pharmacological entities, while edges represent relationships between entities.
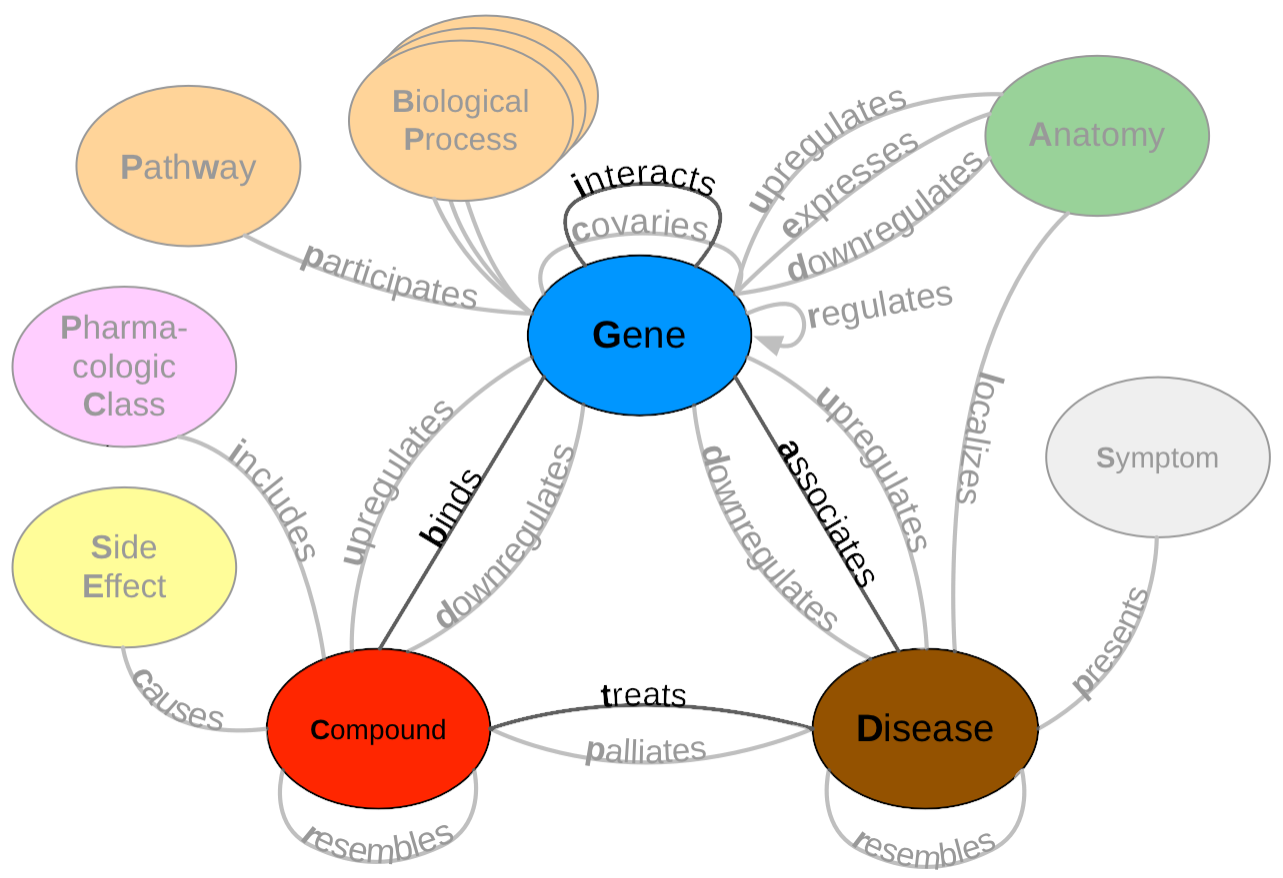
Hetionet v1 contains 47,031 nodes with 11 different data types and 2,250,197 edges that represent 24 different relationship types (Figure 1).
Edges in Hetionet v1 were obtained from open databases, such as the GWAS Catalog [46], Human Interaction database [47] and DrugBank [48].
For this project, we analyzed performance over a subset of the Hetionet v1 edge types: disease associates with a gene (DaG), compound binds to a gene (CbG), compound treating a disease (CtD), and gene interacts with gene (GiG) (bolded in Figure 1).
Figure 1: A metagraph (schema) of Hetionet v1 where biomedical entities are represented as nodes and the relationships between them are represented as edges.
We examined performance on the highlighted subgraph; however, the long-term vision is to capture edges for the entire graph.
Dataset
We used PubTator Central [49] as input to our analysis.
PubTator Central provides MEDLINE abstracts that have been annotated with well-established entity recognition tools including Tagger One [50] for disease, chemical and cell line entities, tmVar [51] for genetic variation tagging, GNormPlus [52] for gene entities and SR4GN [53] for species entities.
We downloaded PubTator Central on March 1, 2020, at which point it contained approximately 30,000,000 documents.
After downloading, we filtered out annotated entities that were not contained in Hetionet v1.
We extracted sentences with two or more annotations and termed these sentences as candidate sentences.
We used the Spacy’s English natural language processing (NLP) pipeline (en_core_web_sm) [54] to generate dependency trees and parts of speech tags for every extracted candidate sentence.
Each candidate sentence was stratified by their corresponding abstract ID to produce a training set, tuning set, and a testing set.
We used random assortment to assign dataset labels to each abstract.
Every abstract had a 70% chance of being labeled training, 20% chance of being labeled tuning, and 10% chance of being labeled testing.
Despite the power of data programming, all text mining systems need to have ground truth labels to be well-calibrated.
We hand-labeled five hundred to a thousand candidate sentences of each edge type to obtain a ground truth set (Table 1).
Table 1: Statistics of Candidate Sentences.
We sorted each abstract into a training, tuning and testing set.
Numbers in parentheses show the number of positives and negatives that resulted from the hand-labeling process.
Relationship
Train
Tune
Test
Disease-associates-Gene (DaG)
2.49 M
696K (397+, 603-)
348K (351+, 649-)
Compound-binds-Gene (CbG)
2.4M
684K (37+, 463-)
341k (31+, 469-)
Compound-treats-Disease (CtD)
1.5M
441K (96+, 404-)
223K (112+, 388-)
Gene-interacts-Gene (GiG)
11.2M
2.19M (60+, 440-)
1.62M (76+, 424-)
Label Functions for Annotating Sentences
The challenge of having too few ground truth annotations is familiar to many biomedical applications that use natural language processing, even when unannotated text is abundant.
Data programming circumvents this issue by quickly annotating large datasets using multiple noisy signals emitted by label functions [45].
We chose to use data programming for this project as it allows us to provide generalizable rules that can be reused in future text mining systems.
Label functions are simple pythonic functions that emit: a positive label (1), a negative label (0), or abstain from emitting a label (-1).
These functions can use different approaches or techniques to emit a label; however, these functions can be grouped into simple categories discussed below.
Once constructed, these functions are combined using a generative model to output a single annotation.
This single annotation is a consensus probability score bounded between 0 (low chance of mentioning a relationship) and 1 (high chance of mentioning a relationship).
We used these annotations to train a discriminative model for the final classification step.
Label Function Categories
Label functions can be constructed in various ways; however, they also share similar characteristics.
We grouped functions into databases and text patterns.
The majority of our label functions fall into the text pattern category (Supplemental Table 2).
Further, we described each label function category and provided an example that refers to the following candidate sentence: “PTK6 may be a novel therapeutic target for pancreatic cancer”.
Databases: These label functions incorporate existing databases to generate a signal, as seen in distant supervision [4].
These functions detect if a candidate sentence’s co-mention pair is present in a given database.
Our label function emits a positive label if the pair is present and abstains otherwise.
If the pair is not present in any existing database, a separate label function emits a negative label.
We used a separate label function to prevent a label imbalance problem, which can occur when a single function labels every possible sentence despite being correct or not.
If this problem isn’t handled correctly, the generative model could become biased and only emit one prediction (solely positive or solely negative) for every sentence.
Text Patterns: These label functions are designed to use keywords or sentence context to generate a signal.
For example, a label function could focus on the number of words between two mentions and emit a label if two mentions are too close.
Alternatively, a label function could focus on the parts of speech contained within a sentence and ensures a verb is present.
Besides parts of speech, a label function could exploit dependency parse trees to emit a label.
These trees are akin to the tree data structure where words are nodes and edges are how each word modifies each other.
Label functions that use these parse trees will test if the generated tree matches a pattern and emits a positive label if true.
For our analysis, we used previously identified patterns designed for biomedical text to generate our label functions [18].
Each text pattern label function was constructed via manual examination of sentences within the training set.
For example, using the candidate sentence above, one would identify the phrase “novel therapeutic target” and incorporate this phrase into a global list that a label function would use to check if present in a sentence.
After initial construction, we tested and augmented the label function using sentences in the tune set.
We repeated this process for every label function in our repertoire.
Table 2: The distribution of each label function per relationship.
Relationship
Databases (DB)
Text Patterns (TP)
DaG
7
30
CtD
3
22
CbG
9
20
GiG
9
28
Training Models
Generative Model
The generative model is a core part of this automatic annotation framework.
It integrates multiple signals emitted by label functions to assign each candidate sentence the most appropriate training class.
This model takes as input a label function output in the form of a matrix where rows represent candidate sentences, and columns represent each label function (\(\Lambda^{nxm}\)).
Once constructed, this model treats the true training class (\(Y\)) as a latent variable and assumes that each label function is independent of one another.
Under these two assumptions, the model finds the optimal parameters by minimizing a loglikelihood function marginalized over the latent training class.
Following optimization, the model emits a probability estimate that each sentence belongs to the positive training class.
At this step, each probability estimate can be discretized via a chosen threshold into a positive or negative class.
This model uses the following parameters to generate training estimates: weight for the l2 loss, a learning rate, and the number of epochs.
We fixed the learning rate to be 1e-3 as we found that higher weights produced NaN results.
We also fixed the number of epochs to 250 and performed a grid search of five evenly spaced numbers between 0.01 and 5 for the l2 loss parameter.
Following the training phase, we used a threshold of 0.5 for discretizing training classes’ probability estimates within our analysis.
For more information on how the likelihood function is constructed and minimized, refer to [55].
Discriminative Model
The discriminative model is the final step in this framework.
This model uses training labels generated from the generative model combined with sentence features to classify the presence of a biomedical relationship.
Typically, the discriminative model is a neural network.
In the context of text mining, these networks take the form of transformer models [31], which have achieved high-performing results.
Their past performance lead us to choose BioBERT [30] as our discriminative model.
BioBERT [30] is a BERT [56] model that was trained on all papers and abstracts within Pubmed Central [57].
BioBERT provides its own set of word embeddings, dense vectors representing words that models such as neural networks can use to construct sentence features.
We downloaded a pre-trained version of this model using huggingface’s transformer python package [58] and fine-tuned it using our generated training labels.
Our fine-tuning approach involved freezing all downstream layers except for the classification head of this model.
Next, we trained this model for 10 epochs using the Adam optimizer [59] with huggingface’s default parameter settings and a learning rate of 0.001.
Experimental Design
Reusing label functions across edge types would substantially reduce the number of label functions required to extract multiple relationships from biomedical literature.
We first established a baseline by training a generative model using only distant supervision label functions designed for the target edge type.
Then we compared the baseline model with models that incorporated a set number of text pattern label functions.
Using a sampling with replacement approach, we sampled these text pattern label functions from three different groups: within edge types, across edge types, and from a pool of all label functions.
We compared within-edge-type performance to across-edge-type and all-edge-type performance.
We sampled a fixed number of label functions for each edge type consisting of five evenly spaced numbers between one and the total number of possible label functions.
We repeated this sampling process 50 times for each point.
Furthermore, we also trained the discriminative model using annotations from the generative model trained on edge-specific label functions at each point.
We report the performance of both models in terms of the area under the receiver operating characteristic curve (AUROC) and the area under the precision-recall curve (AUPR) for each sample.
Next, we aggregated each individual sample’s performance by constructing bootstrapped confidence intervals.
Ensuing model evaluations, we quantified the number of edges we could incorporate into Hetionet v1.
We used our best-performing discriminative model to score every candidate sentence within our dataset and grouped candidates based on their mention pair.
We took the max score within each candidate group, and this score represents the probability of the existence of an edge.
We established edges using a cutoff score that produced an equal error rate between the false positives and false negatives.
Lastly, we report the number of preexisting edges we could recall and the number of novel edges we can incorporate.
Results
Generative Model Using Randomly Sampled Label Functions
Creating label functions is a labor-intensive process that can take days to accomplish.
We sought to accelerate this process by measuring how well label functions can be reused.
We evaluated this by performing an experiment where label functions are sampled on an individual (edge vs. edge) level and a global (collective pool of sources) level.
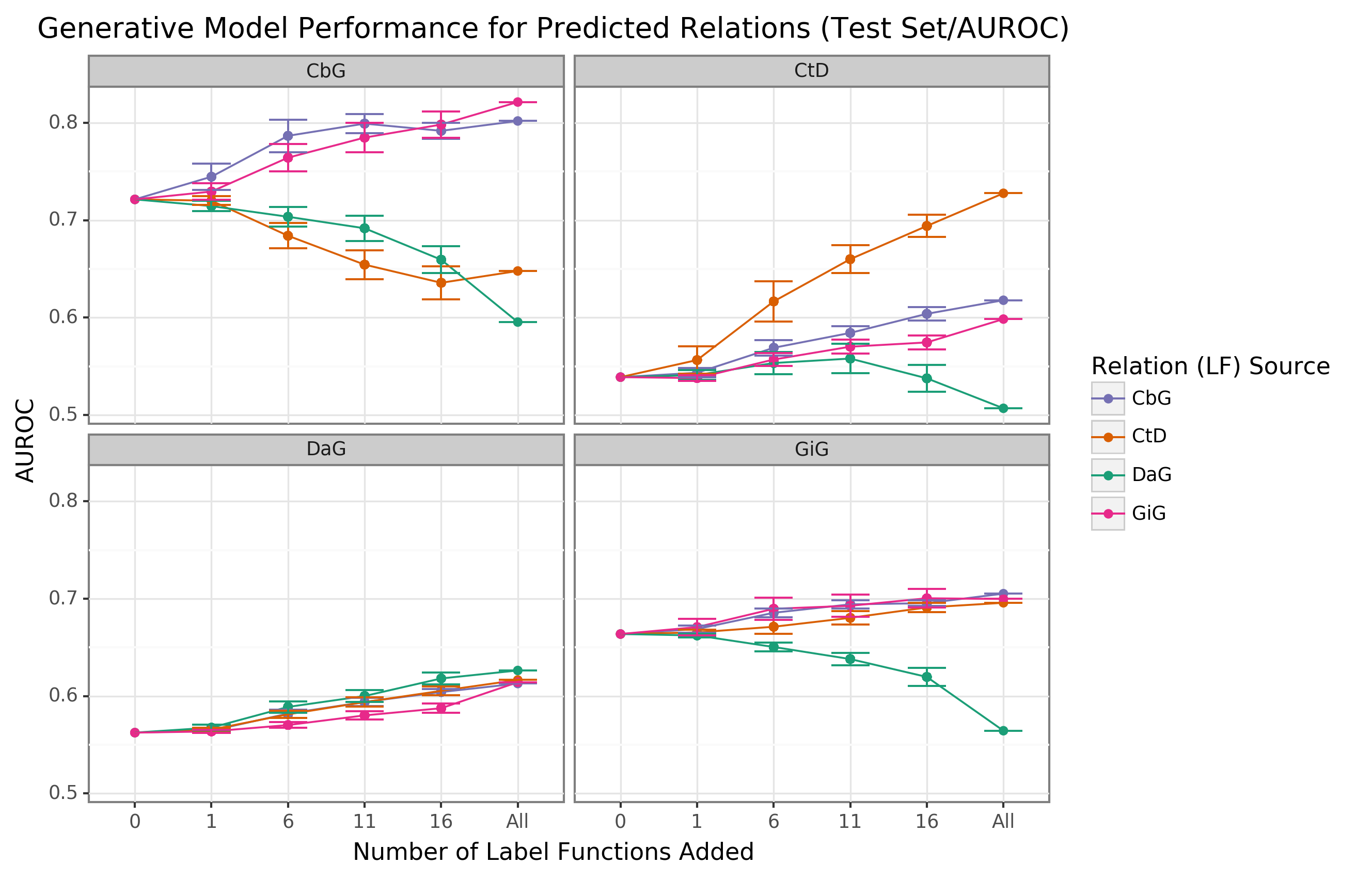
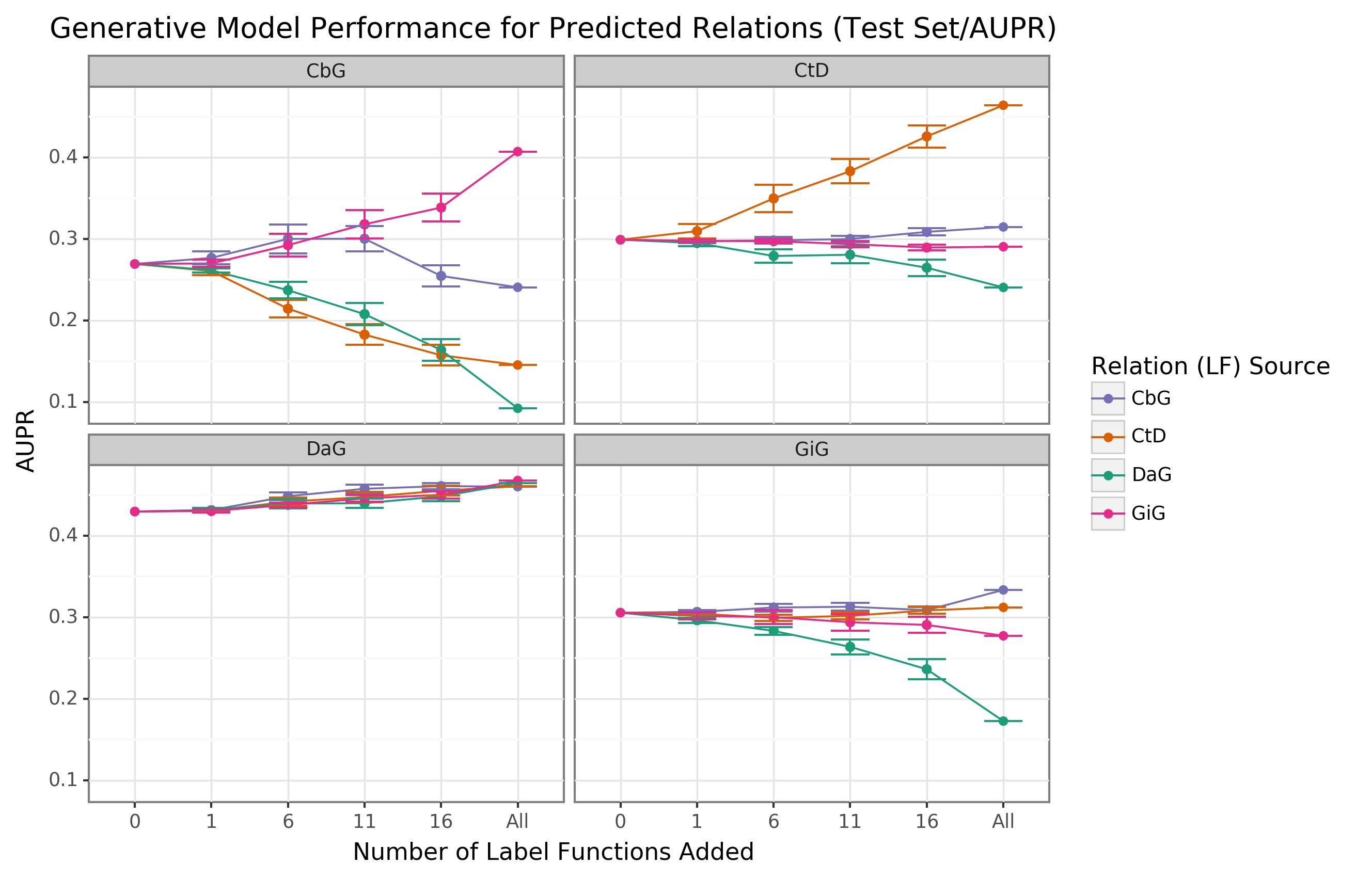
We observed that performance increased when edge-specific label functions were added to an edge-specific baseline model, while label function reuse usually provided less benefit (AUROC Figure 2, AUPR Supplemental Figure 6).
The quintessential example of this overarching trend is the Compound-treats-Disease (CtD) edge type, where edge-specific label functions consistently outperformed transferred label functions.
However, there is evidence that label function transferability may be feasible for selected edge types and label function sources.
Performance increases as more Gene-interacts-Gene (GiG) label functions are incorporated into the Compound-binds-Gene (CbG) baseline model and vice versa.
This trend suggests that sentences for GiG and CbG may share similar linguistic features or terminology that allows for label functions to be reused, which could relate to both describing physical interaction relationships.
Perplexingly, edge-specific Disease-associates-Gene (DaG) label functions did not improve performance over label functions drawn from other edge types.
Overall, only CbG and GiG showed significant signs of reusability.
This pattern suggests that label function transferability may be possible for these two edge types.
Figure 2: Edge-specific label functions perform better than edge-mismatch label functions, but certain mismatch situations show signs of successful transfer.
Each line plot header depicts the edge type the generative model is trying to predict, while the colors represent the source of label functions.
For example, orange represents sampling label functions designed to predict the Compound-treats-Disease (CtD) edge type.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the database-only baseline model (the point at 0).
The y-axis shows the area under the receiver operating curve (AUROC).
Each point on the plot shows the average of 50 sample runs, while the error bars show the 95% confidence intervals of all runs.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
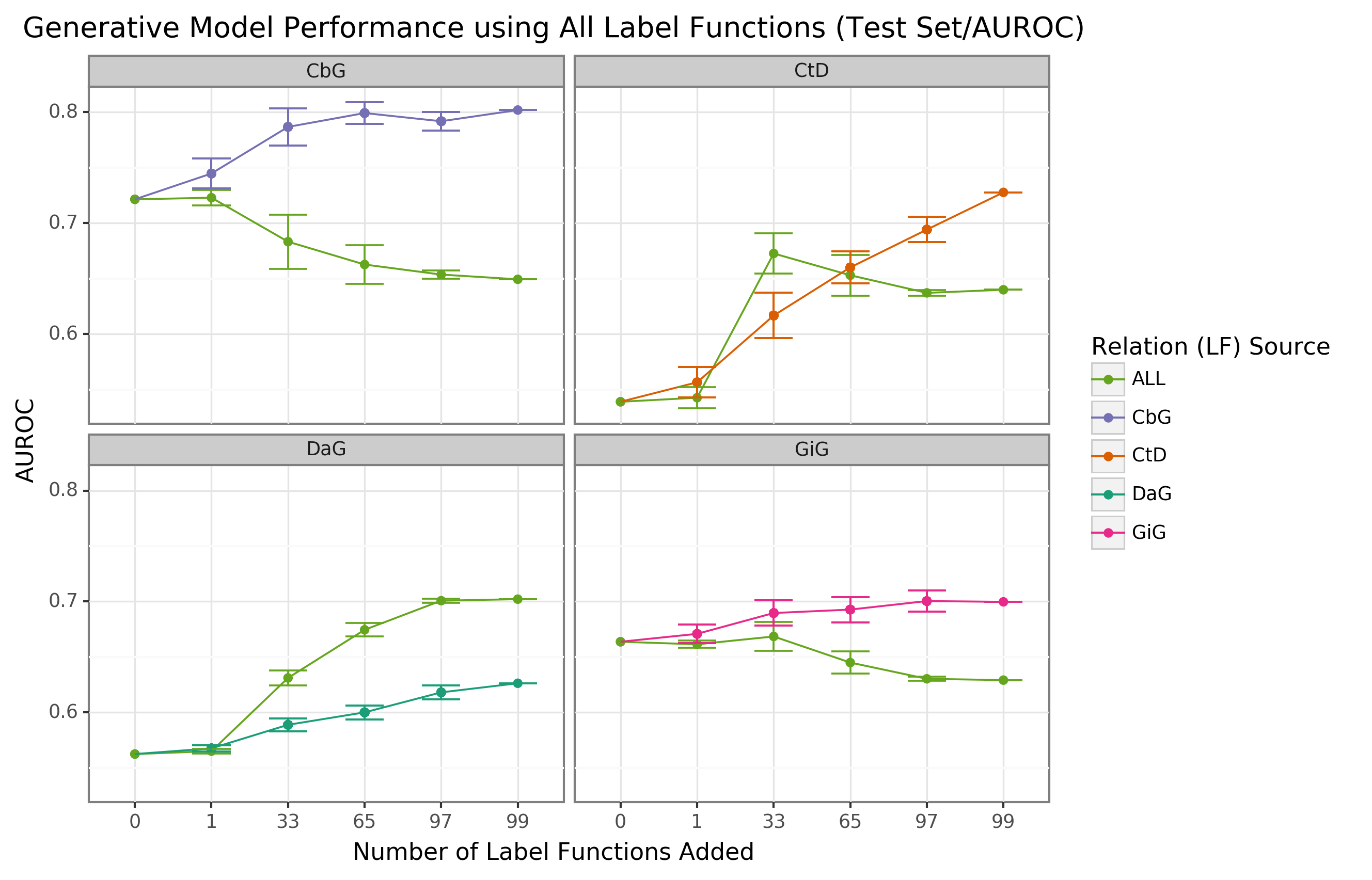
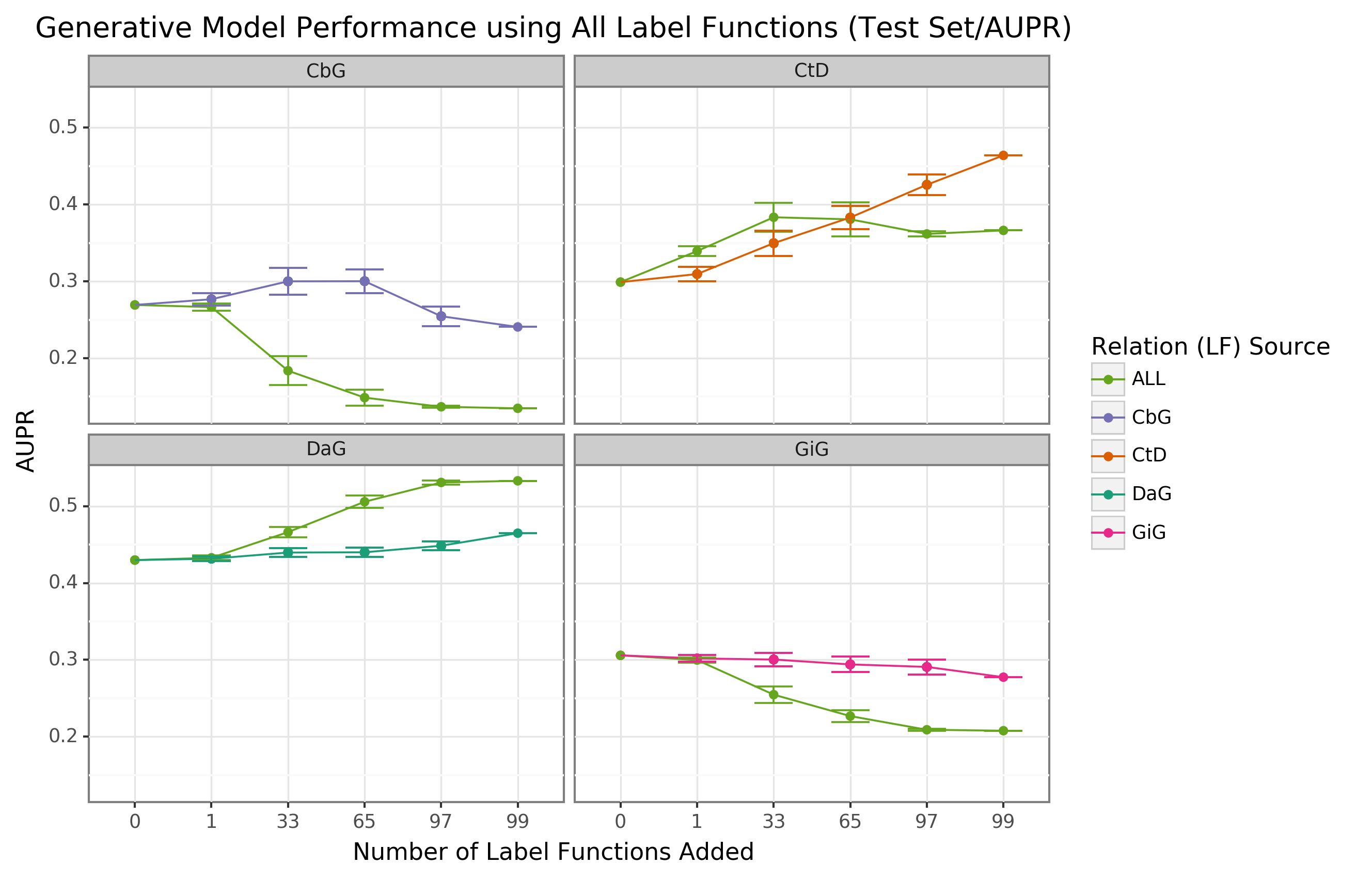
We found that sampling from all label function sources at once usually underperformed relative to edge-specific label functions (Figure 3 and Supplemental Figure 7).
The gap between edge-specific sources and all sources widened as we sampled more label functions.
CbG is a prime example of this trend (Figure 3 and Supplemental Figure 7), while CtD and GiG show a similar but milder trend.
DaG was the exception to the general rule.
The pooled set of label functions improved performance over the edge-specific ones, which aligns with the previously observed results for individual edge types (Figure 2).
When pooling all label functions, the decreasing trend supports the notion that label functions cannot simply transfer between edge types (exception being CbG on GiG and vice versa).
Figure 3: Using all label functions generally hinders generative model performance.
Each line plot header depicts the edge type the generative model is trying to predict, while the colors represent the source of label functions.
For example, orange represents sampling label functions designed to predict the Compound-treats-Disease (CtD) edge type.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the database-only baseline model (the point at 0).
The y-axis shows the area under the receiver operating curve (AUROC).
Each point on the plot shows the average of 50 sample runs, while the error bars show the 95% confidence intervals of all runs.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
Discriminative Model Performance
The discriminative model is intended to augment performance over the generative model by incorporating textual features together with estimated training labels.
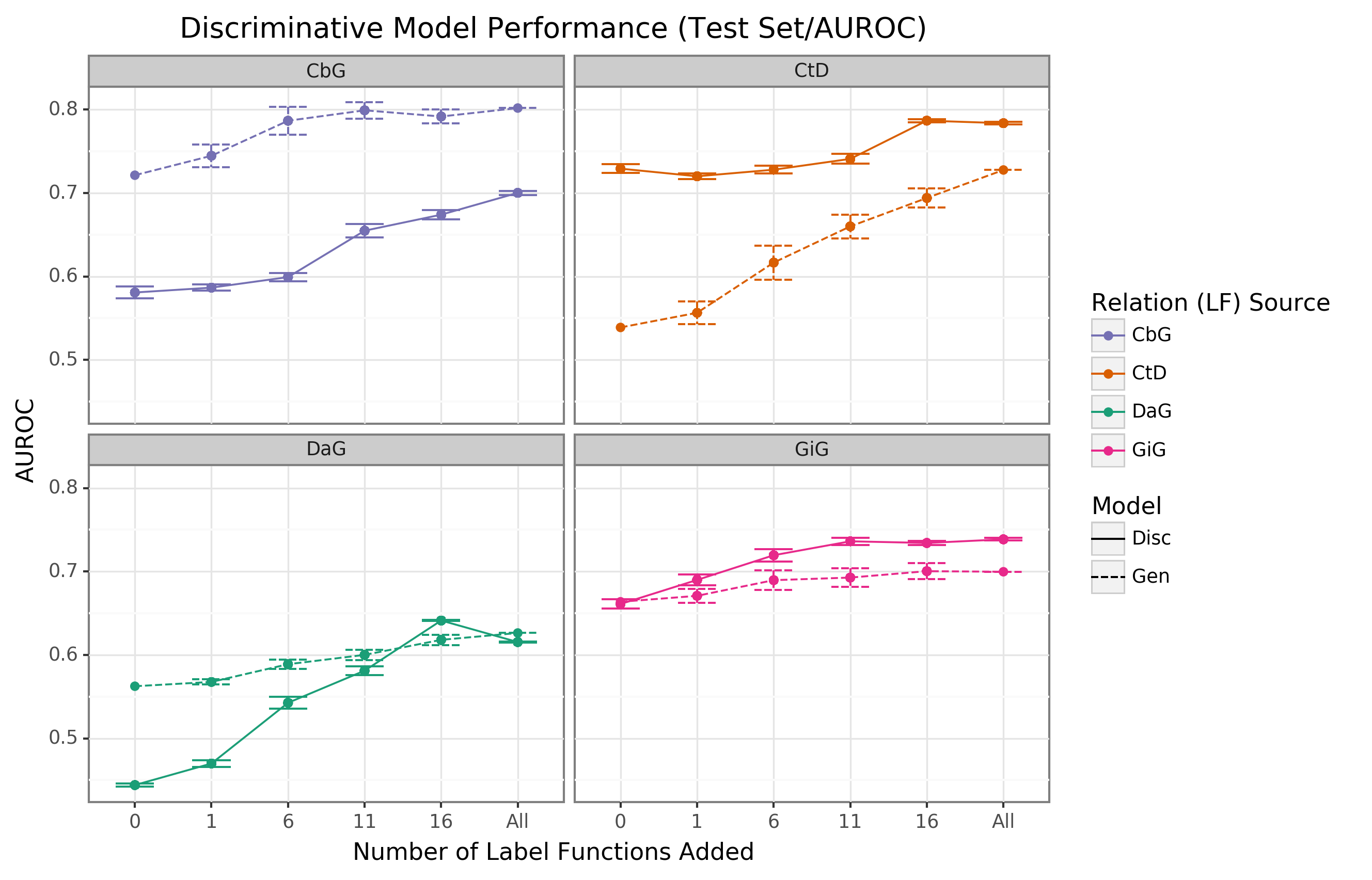
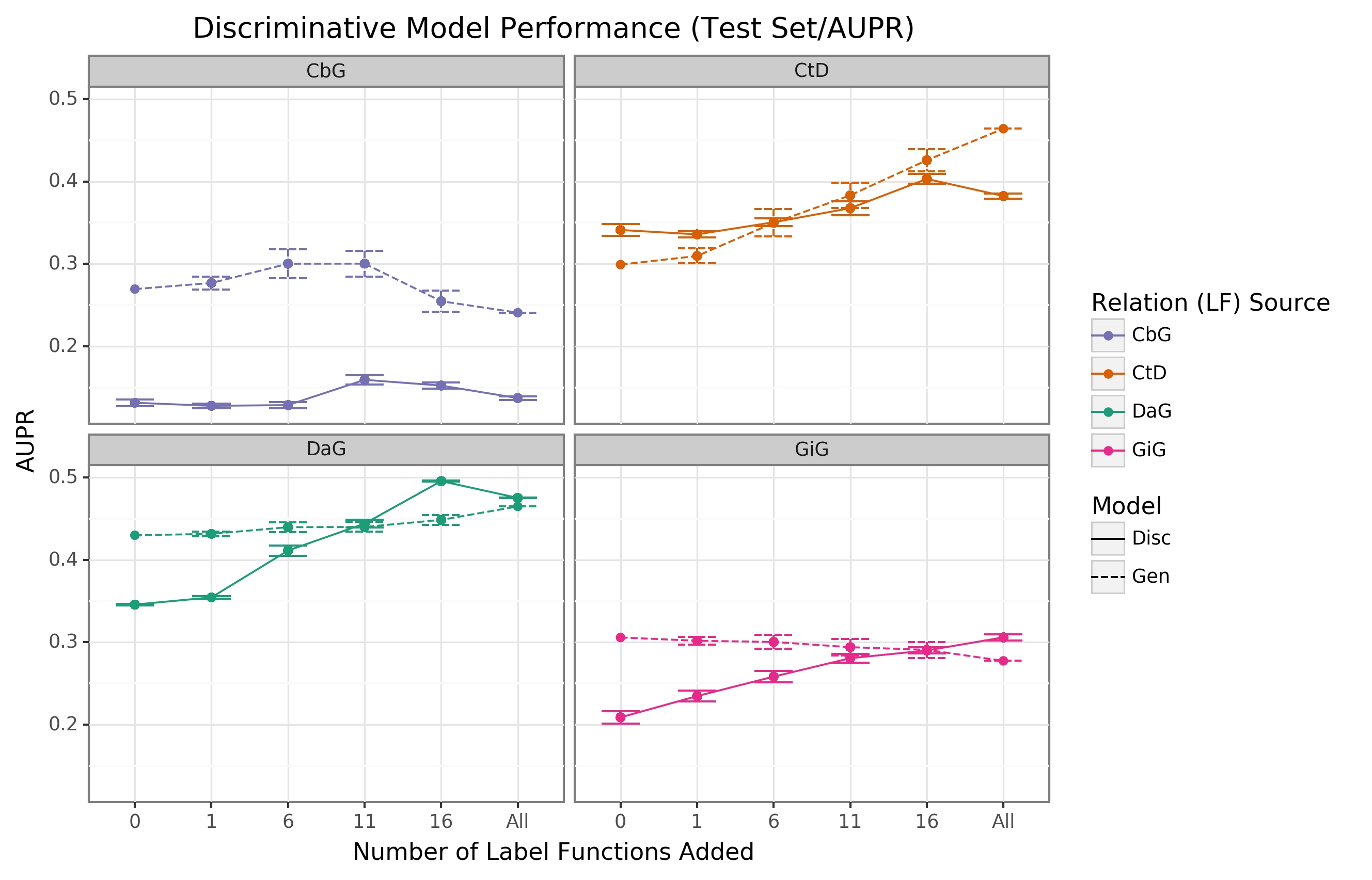
We found that the discriminative model generally outperformed the generative model with respect to AUROC as more edge-specific label functions were incorporated (Figure 4).
Regarding AUPR, this model outperformed the generative model for the DaG edge type.
At the same time, it had close to par performance for the rest of the edge types (Supplemental Figure 8).
The discriminative model’s performance was often poorest when very few edge-specific label functions were incorporated into the baseline model (seen in DaG, CbG, and GiG).
This example suggests that training generative models with more label functions produces better outputs for training for discriminative models.
CtD was an exception to this trend, where the discriminative model outperformed the generative model at all sampling levels in regards to AUROC.
We observed the opposite trend with the CbG edges as the discriminative model was always worse or indistinguishable from the generative model.
Interestingly, the AUPR for CbG plateaus below the generative model and decreases when all edge-specific label functions are used (Supplemental Figure 8).
This trend suggests that the discriminative model might have predicted more false positives in this setting.
Overall, incorporating more edge-specific label functions usually improved performance for the discriminative model over the generative model.
Figure 4: The discriminative model usually improves faster than the generative model as more edge-specific label functions are included.
The line plot headers represent the specific edge type the discriminative model is trying to predict.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the baseline model (the point at 0).
The y axis shows the area under the receiver operating curve (AUROC).
Each data point represents the average of 3 sample runs for the discriminator model and 50 sample runs for the generative model.
The error bars represent each run’s 95% confidence interval.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
Text Mined Edges Can Expand a Database-derived Knowledge Graph
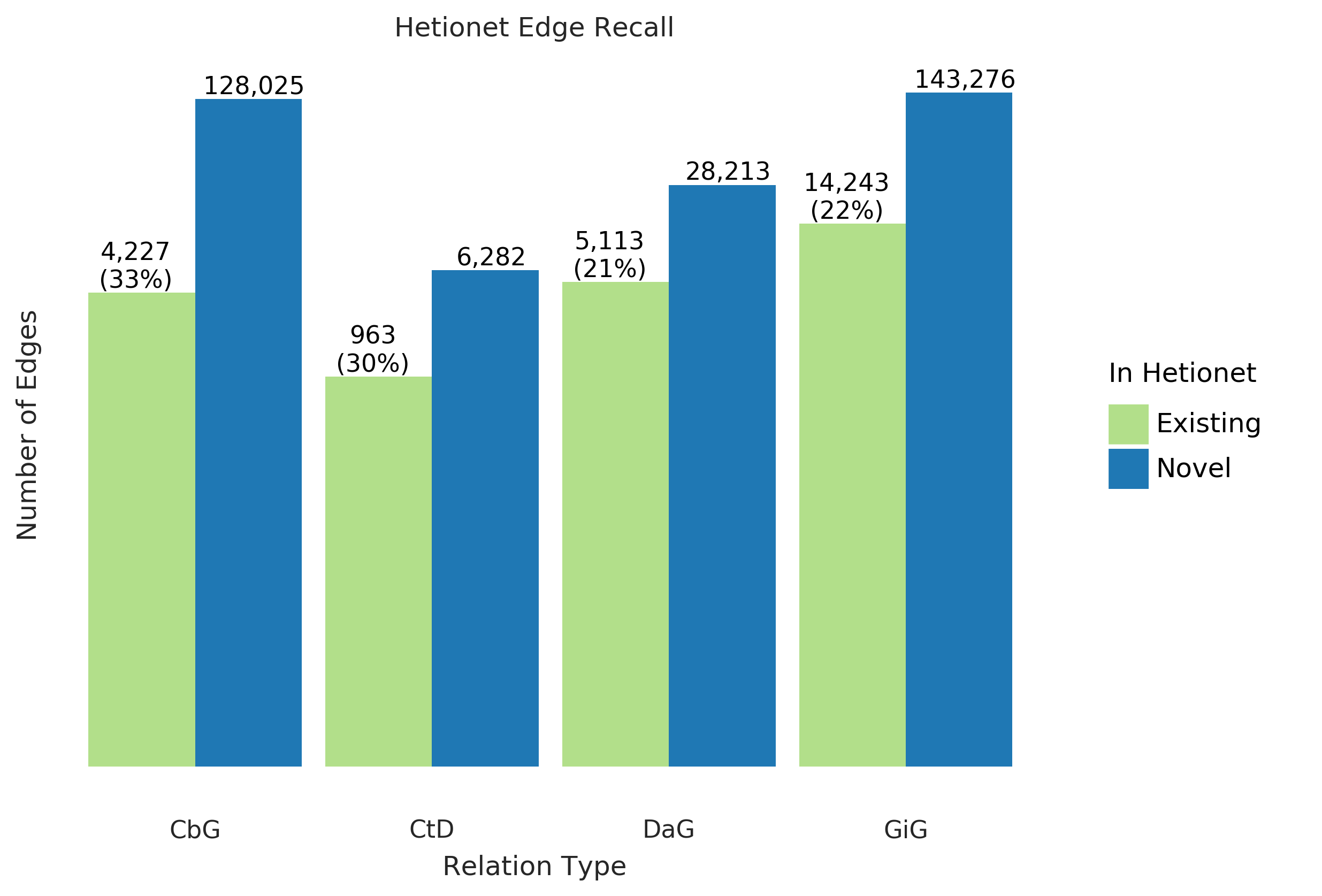
Figure 5: Text-mined edges recreate a substantial fraction of an existing knowledge graph and include new predictions.
This bar chart shows the number of edges we can successfully recall in green and indicates the number of new edges in blue.
The recall for the Hetionet v1 knowledge graph is shown as a percentage in parentheses.
For example, for the Compound-treats-Disease (CtD) edge, our method recalls 30% of existing edges and can add 6,282 new ones.
One of the goals of our work is to measure the extent to which learning multiple edge types could construct a biomedical knowledge graph.
Using Hetionet v1 as an evaluation set, we measured this framework’s recall and quantified the number of edges that may be incorporated with high confidence.
Overall, we were able to recall about thirty percent of the preexisting edges for all edge types (Figure 5) and report our top ten scoring sentences for each edge type in Supplemental Table 3.
Our best recall was with the CbG edge type, where we retained 33% of preexisting edges.
In contrast, we only recalled close to 30% for CtD, while the other two categories achieved a recall score close to 22%.
Despite the modest recall level, the amount of novel edge types remains elevated.
This notion highlights that Hetionet v1 is missing a compelling amount of biomedical information, and relationship extraction is a viable way to close the information gap.
Discussion
Filling out knowledge bases via manual curation can be an arduous and erroneous task [8].
Using manual curation alone becomes impractical as the rate of publications continuously increases.
Data programming is a paradigm that uses label functions to speed up the annotation process and can be used to solve this problem.
However, creating useful label functions is an obstacle to this paradigm, which takes considerable time.
We tested the feasibility of re-using label functions to reduce the number of label functions required for strong prediction performance.
Our sampling experiment revealed that adding edge-specific label functions is better than adding off-edge label functions.
An exception to this trend is using label functions designed from conceptually related edge types (using GiG label functions to predict CbG sentences and vice versa).
Furthermore, broad edge types such as DaG did not follow this trend as we found this edge to be agnostic to any tested label function source.
One possibility for this observation is that the “associates” relationship is a general concept that may include other concepts such as Disease (up/down) regulating a Gene (examples highlighted in our annotated sentences).
These two results suggest that the transferability of label functions is likely to relate to the nature of the edge type in question, so determining how many label functions will be required to scale across multiple relationship types will depend on how conceptually similar those types are.
The discriminator model did not have an apparent positive or negative effect on performance; however, we noticed that performance heavily depended on the annotations provided by the generative model.
This pattern suggests a focus on label function construction and generative model training may be key steps to focus on in future work.
Although we found that label functions cannot be re-used across all edge types with the standard task framing, strategies like multitask [60] or transfer learning [61] may make multi-label-function efforts more successful.
Conclusions
We found that performance often increased through the tested range of 25-30 different label functions per relationship type.
Our finding of limited value for reuse across most edge type pairs suggests that the amount of work required to construct graphs will scale linearly based on the number of edge types.
We did not investigate whether certain individual label functions, as opposed to the full set of label functions for an edge type, were particularly reusable.
It remains possible that some functions are generic and could be used as the base through supplementation with additional, type-specific, functions.
Literature continues to grow at a rate likely to surpass what is feasible by human curation.
Further work is needed to understand how to automatically extract large-scale knowledge graphs from the wealth of biomedical text.
The authors would like to thank Christopher Ré’s group at Stanford University, especially Alex Ratner and Steven Bach, for their assistance with this project.
We also want to thank Graciela Gonzalez-Hernandez for her advice and input with this project.
This work was support by Grant GBMF4552 from the Gordon Betty Moore Foundation.
References
1.
Graph Theory Enables Drug Repurposing – How a Mathematical Model Can Drive the Discovery of Hidden Mechanisms of Action
Ruggero Gramatica, T Di Matteo, Stefano Giorgetti, Massimo Barbiani, Dorian Bevec, Tomaso Aste
Systematic integration of biomedical knowledge prioritizes drugs for repurposing
Daniel Scott Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, Sergio E Baranzini
Distant supervision for relation extraction without labeled data
Mike Mintz, Steven Bills, Rion Snow, Dan Jurafsky
Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2 - ACL-IJCNLP '09 (2009) https://doi.org/fg9q43
BioCreative V CDR task corpus: a resource for chemical disease relation extraction
Jiao Li, Yueping Sun, Robin J Johnson, Daniela Sciaky, Chih-Hsuan Wei, Robert Leaman, Allan Peter Davis, Carolyn J Mattingly, Thomas C Wiegers, Zhiyong Lu
A Proteome-Scale Map of the Human Interactome Network
Thomas Rolland, Murat Taşan, Benoit Charloteaux, Samuel J Pevzner, Quan Zhong, Nidhi Sahni, Song Yi, Irma Lemmens, Celia Fontanillo, Roberto Mosca, … Marc Vidal
DrugBank 5.0: a major update to the DrugBank database for 2018
David S Wishart, Yannick D Feunang, An C Guo, Elvis J Lo, Ana Marcu, Jason R Grant, Tanvir Sajed, Daniel Johnson, Carin Li, Zinat Sayeeda, … Michael Wilson
Transformers: State-of-the-Art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Perric Cistac, Clara Ma, Yacine Jernite, Julien Plu, … Alexander M Rush
Generative Model Using Randomly Sampled Label Functions
Individual Sources
Figure 6: Edge-specific label functions improve performance over edge-mismatch label functions.
Each line plot header depicts the edge type the generative model is trying to predict, while the colors represent the source of label functions.
For example, orange represents sampling label functions designed to predict the Compound treats Disease (CtD) edge type.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the database-only baseline model (the point at 0).
The y-axis shows the area under the precision-recall curve (AUPR).
Each point on the plot shows the average of 50 sample runs, while the error bars show the 95% confidence intervals of all runs.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
Collective Pool of Sources
Figure 7: Using all label functions generally hinders generative model performance.
Each line plot header depicts the edge type the generative model is trying to predict, while the colors represent the source of label functions.
For example, orange represents sampling label functions designed to predict the Compound treats Disease (CtD) edge type.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the database-only baseline model (the point at 0).
The y-axis shows the area under the precision-recall curve (AUPR).
Each point on the plot shows the average of 50 sample runs, while the error bars show the 95% confidence intervals of all runs.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
Discriminative Model Performance
Figure 8: The discriminator model improves performance as the number of edge-specific label functions is added to the baseline model.
The line plot headers represent the specific edge type the discriminator model is trying to predict.
The x-axis shows the number of randomly sampled label functions incorporated as an addition to the baseline model (the point at 0).
The y axis shows the area under the precision-recall curve (AUPR).
Each data point represents the average of 3 sample runs for the discriminator model and 50 sample runs for the generative model.
The error bars represent each run’s 95% confidence interval.
The baseline and “All” data points consist of sampling from the entire fixed set of label functions.
Supplemental Tables
Top Ten Sentences for Each Edge Type
Table 3: Contains the top ten predictions for each edge type. Highlighted words represent entities mentioned within the given sentence.
Edge Type
Source Node
Target Node
Generative Model Prediction
Discriminative Model Prediction
Number of Sentences
In Hetionet
Text
DaG
hematologic cancer
STMN1
1.000
0.979
83
Novel
the stathmin1 mrna expression level in de novo al patient be high than that in healthy person ( p < 0.05 ) , the [stathmin1].{gene_color} mrna expression level in relapse patient with al be high than that in de novo patient ( p < 0.05 ) , and there be no significant difference of stathmin1 mrna expression between patient with [aml].{disease_color} and patient with all .
DaG
breast cancer
INSIG2
1.000
0.979
4
Novel
in analysis of [idc ].{disease_color} cell , the level of [insig2].{gene_color} mrna expression be significantly high in late - stage patient than in early - stage patient .
DaG
lung cancer
GNAO1
1.000
0.979
104
Novel
high [numb].{disease_color} expression be associate with favorable prognosis in patient with [lung adenocarcinoma].{gene_color} , but not in those with squamous cell carcinoma .
DaG
breast cancer
TTF1
1.000
0.977
88
Novel
significant [ttf-1].{gene_color} overexpression be observe in adenocarcinomas harbor egfr mutation ( p = 0.008 ) , and no or significantly low level expression of ttf-1 be observe in [adenocarcinomas].{disease_color} harbor kras mutation ( p = 0.000 ) .
DaG
breast cancer
BUB1B
1.000
0.977
13
Novel
elevated [bubr1].{gene_color} expression be associate with poor survival in early stage [breast cancer].{disease_color} patient .
DaG
Alzheimer’s disease
SERPINA3
1.000
0.977
182
Existing
a common polymorphism within act and il-1beta gene affect plasma level of [act].{gene_color} or il-1beta , and [ad].{disease_color} patient with the act t , t or il-1beta t , t genotype show the high level of plasma act or il-1beta , respectively .
DaG
esophageal cancer
TRAF6
1.000
0.976
15
Novel
expression of traf6 be highly elevated in [esophageal cancer].{disease_color} tissue , and patient with high [traf6].{gene_color} expression have a significantly short survival time than those with low traf6 expression .
DaG
hypertension
TBX4
1.000
0.975
146
Novel
the proportion of circulate [th1].{gene_color} cell and the level of t - bet , ifng mrna be increase in [ht].{disease_color} patient , the expression of ifng - as1 be upregulated and positively correlate with the proportion of circulate th1 cell or t - bet , and ifng expression , or serum level of anti - thyroglobulin antibody / thyroperoxidase antibody in ht patient .
DaG
breast cancer
TP53
1.000
0.975
3481
Existing
hormone receptor status rather than her2 status be significantly associate with increase ki-67 and [p53].{gene_color} expression in triple [- negative ].{disease_color} breast carcinoma , and high expression of ki-67 but not p53 be significantly associate with axillary nodal metastasis in triple - negative and high - grade non - triple - negative breast carcinoma .
DaG
esophageal cancer
COL17A1
1.000
0.975
32
Novel
high [cd147].{gene_color} expression in patient with [esophageal cancer].{disease_color} be associate with bad survival outcome and common clinicopathological indicator of poor prognosis .
CtD
Docetaxel
prostate cancer
0.996
0.964
5614
Existing
docetaxel and atrasentan versus [docetaxel ].{compound_color} and placebo for man with advanced castration - resistant [prostate cancer].{disease_color} ( swog s0421 ) : a randomised phase 3 trial
CtD
E7389
breast cancer
0.999
0.957
862
Novel
clinical effect of prior trastuzumab on combination [eribulin mesylate].{compound_color} plus trastuzumab as first - line treatment for human epidermal growth factor receptor 2 positive locally recurrent or metastatic [breast cancer].{disease_color} : result from a phase ii , single - arm , multicenter study
CtD
Zoledronate
bone cancer
0.996
0.955
226
Novel
[zoledronate].{compound_color} in combination with chemotherapy and surgery to treat [osteosarcoma].{disease_color} ( os2006 ) : a randomised , multicentre , open - label , phase 3 trial .
CtD
0.878
0.954
484
Existing
the role of [ixazomib].{compound_color} as an augment conditioning therapy in salvage autologous stem cell transplant ( asct ) and as a post - asct consolidation and maintenance strategy in patient with relapse multiple myeloma ( accord [ uk - mra [myeloma].{disease_color} xii ] trial ) : study protocol for a phase iii randomise controlled trial
CtD
Topotecan
lung cancer
1.000
0.954
315
Existing
combine chemotherapy with cisplatin , etoposide , and irinotecan versus [topotecan].{compound_color} alone as second - line treatment for patient with [sensitive relapse small].{disease_color} - cell lung cancer ( jcog0605 ) : a multicentre , open - label , randomised phase 3 trial .
CtD
Epirubicin
breast cancer
0.999
0.953
2147
Existing
accelerate versus standard [epirubicin].{compound_color} follow by cyclophosphamide , methotrexate , and fluorouracil or capecitabine as adjuvant therapy for [breast cancer].{disease_color} in the randomised uk tact2 trial ( cruk/05/19 ) : a multicentre , phase 3 , open - label , randomise , control trial
CtD
Paclitaxel
breast cancer
1.000
0.952
10255
Existing
sunitinib plus [paclitaxel].{compound_color} versus bevacizumab plus paclitaxel for first - line treatment of patients with [advanced breast cancer].{disease_color} : a phase iii , randomized , open - label trial
CtD
Anastrozole
breast cancer
0.996
0.952
2364
Existing
a european organisation for research and treatment of cancer randomize , double - blind , placebo - control , multicentre [phase].{disease_color} ii trial of anastrozole in combination with [gefitinib or placebo in hormone].{compound_color} receptor - positive advanced breast cancer ( nct00066378 ) .
CtD
Gefitinib
lung cancer
1.000
0.950
11860
Existing
[gefitinib].{compound_color} versus placebo as maintenance therapy in patient with locally advanced or metastatic [non - small].{disease_color} - cell lung cancer ( inform ; c - tong 0804 ) : a multicentre , double - blind randomise phase 3 trial .
CtD
Docetaxel
prostate cancer
1.000
0.949
5614
Existing
ipilimumab versus placebo after radiotherapy in patient with metastatic castration - resistant [prostate cancer].{disease_color} that have progress after [docetaxel].{compound_color} chemotherapy ( ca184 - 043 ) : a multicentre , randomised , double - blind , phase 3 trial
CtD
Sulfamethazine
lung cancer
0.611
0.949
4
Novel
[tmp].{compound_color} / smz ( 320/1600 mg / day ) treatment be compare to placebo in a double - blind , randomized trial in [patient with newly diagnose].{disease_color} small cell carcinoma of the lung during the initial course of chemotherapy with cyclophosphamide , doxorubicin , and etoposide .
CbG
D-Tyrosine
EGFR
0.601
0.876
3423
Novel
amphiregulin ( ar ) and heparin - binding egf - like growth factor ( hb - [egf].{gene_color} ) bind and activate the egfr while heregulin ( hrg [) act ].{compound_color} through the p185erbb-2 and p180erbb-4 tyrosine kinase .
CbG
Phosphonotyrosine
ANK3
0.004
0.865
1
Novel
at least two domain of p85 can bind to [ank3 ].{gene_color} , and the interaction involve the p85 c - sh2 domain be find to be [phosphotyrosine].{compound_color} - independent .
CbG
Adenosine
ABCC8
0.891
0.860
353
Novel
sulfonylurea act by inhibition of [beta - cell ].{compound_color} adenosine triphosphate - dependent potassium ( k(atp ) ) channel after bind to the sulfonylurea subunit 1 [receptor ( ].{gene_color} sur1 ) .
CbG
D-Tyrosine
AREG
0.891
0.857
22
Novel
amphiregulin ( [ar ) ].{gene_color} and heparin - binding egf - like growth factor ( hb - egf ) bind and activate the egfr while heregulin ( hrg [) act ].{compound_color} through the p185erbb-2 and p180erbb-4 tyrosine kinase .
CbG
D-Tyrosine
EGF
0.602
0.856
389
Novel
upon activation of the receptor for the epidermal growth factor ( [egfr ) ].{gene_color} , sprouty2 undergoe phosphorylation at a conserve [tyrosine ].{compound_color} that recruit the src homology 2 domain of c - cbl .
CbG
D-Tyrosine
CSF1
0.101
0.854
106
Novel
as a member of the subclass iii family of receptor [tyrosine].{compound_color} kinase , kit be closely relate to the receptor for platelet derive growth factor alpha and beta ( pdgf - a and b [) , macrophage colony ].{gene_color} stimulate factor ( m - csf ) , and flt3 ligand .
CbG
D-Tyrosine
ERBB4
0.101
0.848
115
Novel
the efgr family be a group of four structurally similar [tyrosine ].{compound_color} kinase ( egfr , her2 / neu , erbb-3 [, and erbb-4].{gene_color} ) that dimerize on bind with a number of ligand , include egf and transform growth factor alpha .
CbG
D-Tyrosine
EGFR
0.969
0.848
3423
Novel
the [epidermal growth factor receptor ].{gene_color} be a member of type - -pron- growth factor receptor [family ].{compound_color} with tyrosine kinase activity that be activate follow the binding of multiple cognate ligand .
CbG
D-Tyrosine
VAV1
0.601
0.842
187
Novel
stimulation of quiescent rodent fibroblast with either epidermal or platelet - derive growth factor induce an increase affinity of vav for cbl - b and result in the [subsequent ].{gene_color} formation of a vav - [dependent ].{compound_color} trimeric complex with the ligand - stimulate tyrosine kinase receptor .
CbG
Tretinoin
RORB
0.601
0.840
7
Novel
the retinoid z receptor beta ( [rzr beta ) ].{gene_color} , an orphan receptor , be a member of the [retinoic acid].{compound_color} receptor ( rar)/thyroid hormone receptor ( tr ) subfamily of nuclear receptor .
CbG
L-Tryptophan
TACR1
0.891
0.839
4
Novel
these result suggest that the [tryptophan ].{compound_color} and quinuclidine series of nk-1 antagonist bind to similar bind site on the human [nk-1 receptor ].{gene_color} .
GiG
CYSLTR2
CYSLTR2
0.967
0.564
37
Novel
the bind pocket of [cyslt2 ].{gene2_color} receptor and the proposition of the interaction mode between [cyslt2 ].{gene1_color} and hami3379 be identify .
GiG
RXRA
PPARA
1.000
0.563
143
Novel
after bind ligand , the [ppar ].{gene2_color} - y receptor heterodimerize [with ].{gene1_color} the rxr receptor .
GiG
RXRA
RXRA
0.824
0.551
1101
Existing
nuclear hormone receptor , for example , bind either as homodimer or as heterodimer with [retinoid x receptor ].{gene1_color} ( [rxr ) ].{gene2_color} to half - site repeat that be stabilize by protein - protein interaction mediate by residue within both the dna- and ligand - bind domain .
GiG
ADRBK1
ADRA2A
0.822
0.543
3
Novel
mutation of these residue within the [holo - alpha(2a)ar diminish grk2-promoted].{gene2_color} phosphorylation [of ].{gene1_color} the receptor as well as the ability of the kinase to be activate by receptor binding .
GiG
ESRRA
ESRRA
0.001
0.531
308
Existing
the crystal structure of the ligand bind domain ( lbd ) of the estrogen - relate receptor [alpha ].{gene2_color} ( [erralpha , ].{gene1_color} nr3b1 ) complexe with a coactivator peptide from peroxisome proliferator - activate receptor coactivator-1alpha ( pgc-1alpha ) reveal a transcriptionally active conformation in the absence of a ligand .
GiG
GP1BA
VWF
0.518
0.527
144
Existing
these finding indicate the novel bind site require for [vwf ].{gene2_color} binding of human [gpibalpha ].{gene1_color} .
GiG
NR2C1
NR2C1
0.027
0.522
26
Novel
the human [testicular receptor 2].{gene1_color} ( [tr2 )].{gene2_color} , a member of the nuclear hormone receptor superfamily , have no identify ligand yet .
GiG
NCOA1
ESRRG
0.992
0.518
1
Novel
the crystal structure of the ligand bind domain ( lbd ) of the estrogen - relate receptor [3 (].{gene2_color} err3 ) complexe with a steroid receptor [coactivator-1 (].{gene1_color} src-1 ) peptide reveal a transcriptionally active conformation in absence of any ligand .
GiG
PPARG
PPARG
0.824
0.504
2497
Existing
although these agent can bind and activate an orphan nuclear receptor , [peroxisome proliferator - activate].{gene2_color} receptor [gamma ( ].{gene1_color} ppargamma ) , there be no direct evidence to conclusively implicate this receptor in the regulation of mammalian glucose homeostasis .
GiG
ESR2
ESR1
0.995
0.503
1715
Novel
ligand bind experiment with purify [er alpha].{gene2_color} and [er beta].{gene1_color} confirm that the two phytoestrogen be er ligand .
GiG
FGFR2
FGFR2
1.000
0.501
584
Existing
receptor modeling of [kgfr].{gene1_color} be use to identify selective kgfr tyrosine kinase ( tk ) inhibitor molecule that have the potential to bind selectively to the [kgfr].{gene2_color} .